

通过:达拉斯利德尔博士,副教授兼系主任英语,奥格斯堡学院
Marshall McLuhan is supposed to have said that “the content of a new medium is always an old medium.” He intended the observation as wry cultural criticism,but as a literary historian I am grateful every day that so many new research media are now brimming with the contents of great past media: newsstands, theatres, libraries, music halls, stereopticons, and magic lantern shows. Lately I have started to hope that the benefits of these research tools may go far beyond the convenience of having so many original texts, images, and artifacts instantly available. New methods of “data-mining” using database archives, if we do them creatively and well, may help researchers better understand how the old media forms themselves worked and developed.
该hope grows from recent experience. I started “data mining” the Gale时Digital Archivenot long ago, after struggling for nearly twenty years with questions about Victorian newspapers that traditional archival research had been unable to answer.
我的第一份工作的大学是作为一个伟大的小堪萨斯日报记者,当我去了维多利亚时代的文学研究生院我想了解维多利亚时代将读他们的报纸的好方法。我查了伦敦的精装卷时for January 1868 out of the University of Iowa Library, walking home a mile with the enormous thing under my arm (imagine a broadsheet-sized hardback), and spent the next month reading该时at breakfast instead of theIowa City Press-Citizen. It was a wonderful experience—I followed a thrilling missing-persons case from start to finish—and did help me understand the Victorians better.
It also left me with big questions, because该时一点也不像我一起长大的报纸,一个我所工作过,而出国留学,甚至是同一时代的美国报纸我见过的英国报纸。它的新闻体裁不熟悉,没有“倒金字塔”的故事,新闻有时表现为哪些参与者的事件曾表示,近逐字记录。本文似乎基于比我以为所有的新闻曾跟随者完全不同的原则。这也是阅读的乐趣巨大。如何做它的话语工作?这种形式是如何发展?我学的标准报纸的历史,但我什么,是正在进行式,这里的问题不是那些书似乎写答案的人。
I found this frustrating, but only for a little while. I was an academic-in-training looking for things to research, and interesting questions no one had answered were golden discoveries. I worked on pieces of the puzzle over years, writing articles about newspaper anonymity, the origins of the editorial article, and even that exciting 1868 missing persons case. Eventually I wrote a book on Victorian journalism in relation to literature.
所有的工作我用我的方法好teachers and librarians in graduate school had taught me: immersion in the primary print sources and wide reading in secondary ones. My bigger questions about newspapers, however, were not being illuminated by those methods. Someone can become expert in Jane Austen and Charlotte Bronte through sheer immersion in their printed words, because it is possible to read and dwell upon every word they published. Newspapers were reservoirs of text published in un-dwell-upon-able orders of magnitude. I eventually figured out that the first hundred years of该时alone must contain twice as much text as every novel—good, bad, or awful—ever published in Victorian Britain. How many people could claim to be well-read in Victorian fiction if Charlotte Bronte alone had written 14,000 books? As I absorbed those numbers, thinking that I could deeply understand a Victorian newspaper just by reading it long enough seemed silly.
当我的研究图书馆所获得的时Digital Archivemy hopes of adding something more substantial to knowledge of Victorian journalism revived. The user interface was designed around word searches and browsing, but as I searched and browsed I thought there might be other ways to use this tool for what Franco Moretti calls “distant reading” of large amounts of text all at once. It is difficult for a human to read, much less count, every word on a newspaper page, but this database could generate downloadable files of any page on demand, and I discovered that the size of the download was a function of the amount of text on the original page. I chose papers at five-year intervals, saved their page images, compared the file sizes, and found I had a rough way to empirically measure a hundred years of the paper’s growth as a form of text storage, something no scholarly source provided.
After many similar experiments I longed to work “under the hood” of the时Digital Archive–not just to leverage the existing interface, but to ask questions and get answers from the original data. I am grateful that Gale was willing to work with me, and eventually provided information from the records used to create the database. At that point I began to do still more intensive forms of what might be called data mining,
I am still new to what is now being called the “digital humanities,” however, and basic mistakes I made while doing new media work on old media questions may be worth sharing with those thinking about such projects themselves, or assisting someone else in doing them.
For example, below this paragraph is one of the first dismaying results of my attempts at data mining: an image burned into my memory as the Blue Blob of Despair. I had arranged with Gale to have the database of the时Digital Archive搜索记录在每一天的纸上的字和字符总数的计数。这一点,我认为,将是十九世纪的增长图片该时I had wanted for years, in complete and unmatched detail—one data point per day. When the information arrived I opened it in a near-frenzy of anticipation and generated a scatter plot, expecting to see a slim smooth curve of growth. This is what appeared instead:
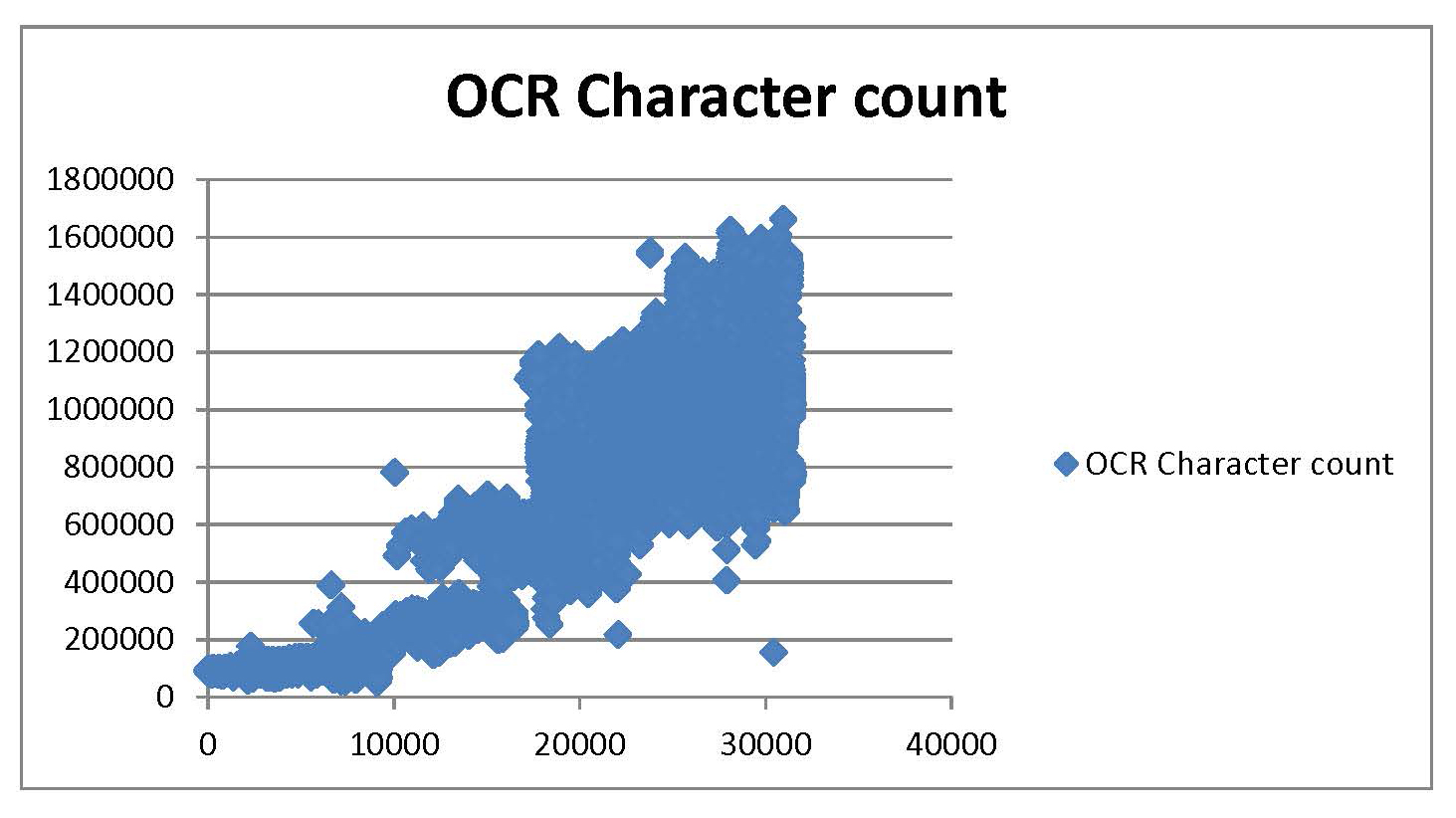
I had believed getting thedata将意味着得到回答,并且还认为,我清楚地知道答案是什么。此Blob的图像传达的第一个信息是你是完全错误的。第二个是你在工作,待办事宜的地块
Thank goodness the first message was an overstatement—the second was not. Eventually the Gale data did give me good answers. My original ideas about how该时必须证明是非常简单化了,但是,我错了十九世纪已经制定,并在需要努力工作把我的权利。从那时起,我已经跟年轻的研究人员在考虑浸渍他们的脚趾到数据挖掘,我已经提供咨询的三个密切相关的部分。
1. Let it be ugly, messy, and uncomfortable
在人文,我们平时学习成品人类手艺,许多或大多数原先作出与观众交流的。它们的含义是密集的或困难的,但有人创造了他们传达一个信息。数据挖掘的信息,即使是那些相同的产品,往往需要不同的形状,在丑态研究者没有人预成形为我们的需要传递的信息。我们的反应是防守简化和去丑化马上做“按摩”的数据,以消除异常值,找到关于这一点似乎是清楚的位平均值和集中趋势,而精矿。我敦促新的数据矿工以保持数据完整和维护它必须说的一切。说到这,
2.让ittell您what it means.
研究人员和图书馆员专业解释了ners and interpreters, and those of us with hard-won years of expertise can be uncomfortable when looking at a genuine unknown. The urge to immediately explain new data in terms of some known frame or story is remarkably powerful. It was only after I stopped desperately trying to make the Blue Blob’s original data mean only what I had formerly wanted it to mean and lived with its details for a few weeks that its true patterns and structures became clear. So,
3. Plan to figure it out over cycles and processes, not all at once.
我们中的许多教迭代的思想给我们的学生,但是,当我们自己的研究问题(和就业)都参与,我们希望得到的答案,并发表论文。我生成并重新生成的蓝色斑点在不同尺度和尺寸段数周之前,我想我明白如何旗下主要有三大模式可能已被的生产发展历史中产生的报纸和它是几个月后,当我想通了有一个显著第四模式理解为好。
随着新媒体的一个旧媒介的形态上的角度来看,我想我终于有更多的了解我早就想如何维多利亚的时在我的爱荷华市的早餐桌上了它的形状和希望很快公布其历史的新观点。电子媒体档案的绝对数量和可用性,然而,这意味着必须有数百个类似的项目待兴回答很多类似的问题。这可能需要一点点巧思,或许反对或周围工具的目的,但有些类型的数据挖掘,现在是内任何图书馆用户的影响力,和有趣的,意想不到的答案,我们的许多最大的研究问题可能从来没有过的方式工作接近。